
VMware ESXi 6.7: Recurring host hardware sensor state alarm
If you found this blog post because you are searchting for a solution for a FAN FAILURE on your ProLiant Gen10 HW after applying the latest ESXi 6.7 patches, then use this shortcut for the workaround: Fan health sensors report false alarms on HPE Gen10 Servers with ESXi 6.7
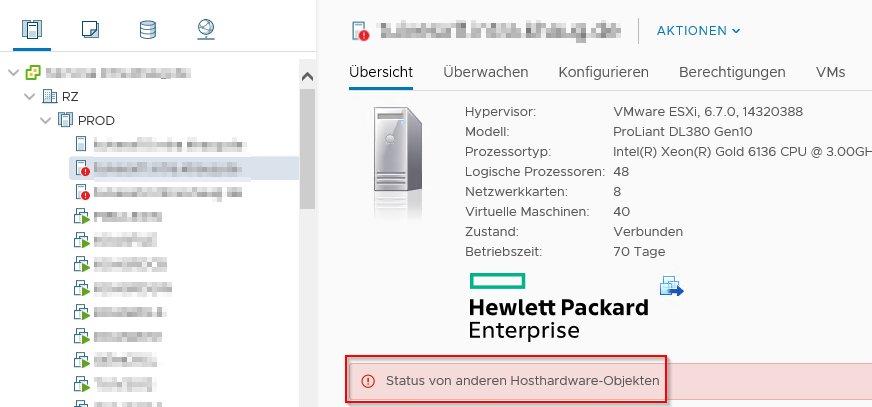
I had a really annoying problem at one of my customers. After deploying new VMware ESXi hosts (HPE ProLiant DL380 Gen10) along with an upgrade of the vCenter Server Appliance to 6.7 U2, the customer reported recurring host hardware sensor state alarm messages in the vCenter for all hosts.
Patrick Terlisten/ vcloudnine.de/ Creative Commons CC0
After acknowledging the alarm, it recurred after a couple of minutes or hours. The hardware was finde, no errors or warnings were noticed in the ILO Management Log. But the vCenter reported periodically a Sensor -1 type error in the Events window. The /var/log/syslog.log contained messages like this:
2019-11-29T04:39:48Z sfcb-vmw_ipmi[4263212]: IpmiIfcSelGetInfo: IPMI_CMD_GET_SEL_INFO cc=0xc1
2019-11-29T04:39:49Z sfcb-vmw_ipmi[4263212]: IpmiIfcSelGetInfo: IPMI_CMD_GET_SEL_INFO cc=0xc1
2019-11-29T04:39:50Z sfcb-vmw_ipmi[4263212]: IpmiIfcSelGetInfo: IPMI_CMD_GET_SEL_INFO cc=0xc1
2019-11-29T04:39:51Z sfcb-vmw_ipmi[4263212]: IpmiIfcSelGetInfo: IPMI_CMD_GET_SEL_INFO cc=0xc1
2019-11-29T04:39:52Z sfcb-vmw_ipmi[4263212]: IpmiIfcSelGetInfo: IPMI_CMD_GET_SEL_INFO cc=0xc1
Sure, you can ignore this. But you shouldn’t ignore this, because these events can result in the vCenter database increasing in size. vCenter can crash once the SEAT partition size goes above the 95% threshold. So you better fix this!
Long story short: This bug is fixed with the latest November updates for ESXi 6.7 U3. A workaround is to disable the WBEM service. The WBEM service might be enabled after a reboot. In this case you have to disable the sfcbd-watchdog service.
But the best way to solve this is to install the latest patches (VMware ESXi 6.7, Patch Release ESXi670-201911001)